Revise Blog - Building a post-AI word processor
The best AI model for proofreading (we tested them all)
We’ve tested 27 AI models on a large scale proofreading benchmark. Here's how they stack up.
You probably use AI to review your writing, but have you ever wondered which models you should be using for this? We did, so we built a proofreading benchmark to answer that with hard data.
ErrataBench uses a dataset of English text totaling 99,000 words – literature, legal writing, technical manuals – corrupted with a wide variety of realistic writing errors. Each model is asked to find and fix as many of these as it can, and judged by its completeness. Here is what we learned.
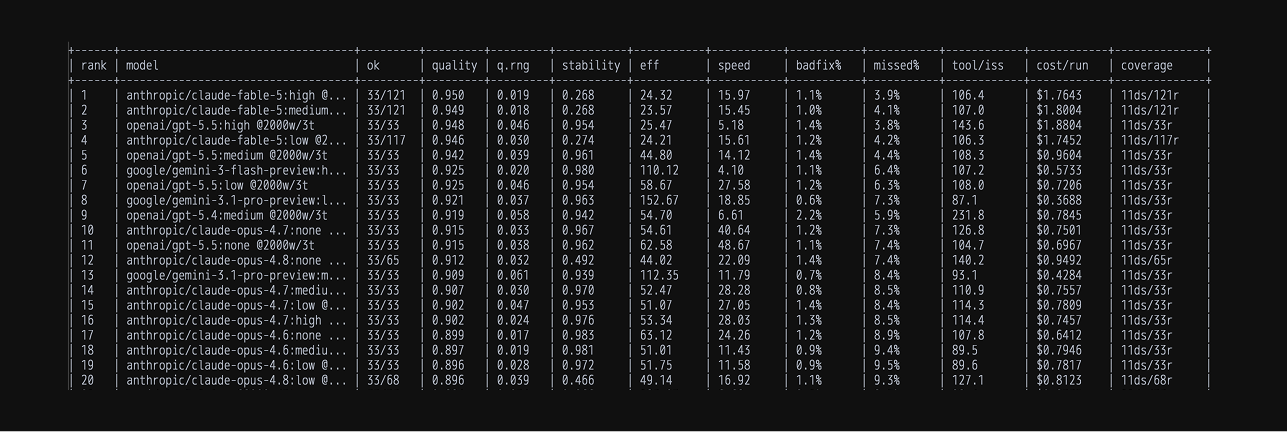
TL;DR: which model is the best?
As of July 2026, Claude Fable 5 is the best AI model for proofreading, scoring highest with medium reasoning. GPT 5.5 is a very close second specifically with high reasoning. Overall Fable wins on quality and cost, and it's also 3 times faster! Fable fixed 15 errors per minute, while GPT fixed only 5 per minute because it relied on more reasoning to perform at the same level.
So if you have access to Fable 5 and you want the highest quality results, use Fable. It's the proofreading champ. If you don't, GPT 5.5 with high reasoning is basically just as good - it beats every other Claude model including Opus 4.8.
Some other noteworthy mentions based on the full data:
- Best value: Gemini 3 Flash. It lands within a couple of points of the leaders at a fraction of the price – ideal for routine passes over everyday documents.
- If you're going to use Opus, use it with no reasoning. All Opus models (4.6, 4.7, 4.8) seem to do best at proofreading with no reasoning at all!
- GLM 5.1 and 5.2 are mention-worthy – they offer a cost-quality trade-off that no other model can beat, with GLM 5.1 scoring just under 90%.
- Grok 4.1 (medium) is an even more cost-effective option, if you're okay with a modest quality drop. It scored just over 85% on our benchmark and costs about 15x less than Fable 5 and GPT 5.5.
- There are certain models it just never makes sense to use, such as Claude Sonnet (inferior to Gemini and GLM) and Grok 4.2.
The top 5 models by quality overall are below. See the full results for more data and scatterplots.
| # | Model | Maker | Reasoning | Fix rate | Missed | Bad fixes |
|---|---|---|---|---|---|---|
| 1 | Claude Fable 5 | Anthropic | High | 95.0% | 3.9% | 1.1% |
| 2 | GPT-5.5 | OpenAI | High | 94.8% | 3.8% | 1.4% |
| 3 | Gemini 3 Flash | High | 92.5% | 6.4% | 1.1% | |
| 4 | Gemini 3.1 Pro | Low | 92.1% | 7.3% | 0.6% | |
| 5 | GPT-5.4 | OpenAI | Medium | 91.9% | 5.9% | 2.2% |
If you want to try different models, you can! Revise is an agentic document editor with support for GPT, Claude, Gemini, and Grok all in one.
Try it yourself. Paste or upload the document you want to proofread below and edit it with AI right in your browser — try it with GPT-Mini and Claude Haiku for free, or access all the top models with a paid plan. No installation or API key required.
How we tested every model
A proofreading benchmark only means something if the test is realistic. Here’s the short version of how ErrataBench works:
- Real text, real errors. We start from genuine source documents across 11 datasets — novels, legal text, scientific writing, nearly 99,000 words in all — and use a model pair to seed small, realistic mistakes drawn from a taxonomy of error categories, with a second model reviewing each one before it’s accepted.
- No cheat sheet. Each model is asked to proofread carefully, but is never told what kinds of errors are hidden or how many there are — just like a real editing job.
- The same tools for everyone. Models work through a simple agent loop with find-and-replace tools, get the same text chunks and the same number of turns, and are graded by an LLM judge on whether each fix is actually correct.
Every model gets the identical prompt, tools, and text — so the only variable is the model itself. Full methodology, source code, and raw results are published and reproducible.
Two columns in the results table matter as much as the headline fix rate: missed counts the errors a model never touched (a thoroughness problem), and bad fixes counts the changes it attempted that were actually wrong. The second is the dangerous one — a model that “corrects” text incorrectly makes your writing worse. The best models keep bad fixes near 1%.
Accuracy vs. cost: the smart-money picks
The most accurate model isn’t always the one you should reach for. Proofreading is often high-volume — a long report, a whole manuscript, a stack of documents — so cost and speed matter.
At the very top the choice is unusually easy: Claude Fable 5 leads on quality and costs less than its closest rival, GPT-5.5, which needs high reasoning (and roughly three times the time) to match it. Below the flagships, you don’t have to pay top dollar for near-top quality: Gemini 3 Flash lands within a couple of points at a fraction of the price, GLM-5.1 scores just under 90% for even less, and Grok 4.1 runs about 15x cheaper than the flagships if you can accept a modest quality drop.
That’s the whole argument for not marrying a single model: use a fast, cheap one for quick passes and escalate to a flagship for the writing that really matters. You can explore the full accuracy-vs-cost tradeoff — plus speed and consistency — on the interactive ErrataBench scatterplot.
What even the best models still get wrong
No model is perfect, and the errors they miss aren’t random. Aggregated across every model we tested, the easiest category to catch is spelling & word form — the obvious typos a basic checker would flag too, resolved about 90% of the time. The hardest is punctuation & sentence boundaries, resolved only around 76% of the time — the subtle, judgment-heavy issues where reasonable editors can disagree. The full results break performance down by error category.
The practical lesson: AI proofreading is excellent, but it’s a collaborator, not an oracle. You still want to see and approve what it changes — which is why the how of AI proofreading matters as much as which model.
The best way to proofread with AI (not just the best model)
Picking a model is half the battle. The other half is the tool you run it in. Pasting paragraphs into a chatbot and copying results back is slow, loses your formatting, and — worst of all — gives you no easy way to see exactly what changed.
Revise is a word processor with the AI built into the editor, designed for exactly this:
- Every top model, one click away. Because Revise is multi-provider, you can proofread with Claude Fable 5, run a cheap second pass with Gemini 3 Flash, and get a second opinion from GPT-5.5 — all in the same document, no accounts or API keys to juggle.
- Whole-document context. The AI reads your entire draft, so it catches inconsistencies a paragraph-at-a-time chatbot never would — a term spelled two ways, a tense that drifts.
- Tracked changes you control. Every fix appears as a red/green diff you accept or reject one by one. The AI proposes; you decide. Nothing is overwritten silently.
- Full revision history. Scrub back through every version to see exactly how the document evolved and which edits came from you versus the AI.
In other words, Revise turns “which model is best” from a one-time bet into a dial you can turn per task — with the review controls that make it safe to let AI touch a document that matters.
The bottom line
What’s the best AI model for proofreading?
Claude Fable 5. It tops ErrataBench on quality, costs less than its closest rival, and is about three times faster. If you don’t have access to Fable, GPT-5.5 with high reasoning is effectively tied on quality — and Gemini 3 Flash is the value pick for everyday passes.
Is ChatGPT or Claude better at it?
At the very top, Claude — Fable 5 leads on quality, cost, and speed. But it flips below the leaders: GPT-5.5 beats every other Claude model, including Opus 4.8. There’s no provider-loyalty answer here; it depends on which two models you’re comparing.
How accurate is AI proofreading, really?
The leaders find and correctly fix more than 90% of errors (the best, Claude Fable 5, hits 95%) and rarely break anything — but they’re strongest on mechanical mistakes and weakest on judgment calls like punctuation and sentence boundaries. Treat the AI as a collaborator and review its changes.
And since the models keep leaping ahead of each other, the smartest move isn’t to pick one forever — it’s to use a tool that lets you switch. Try it on your own writing: paste a document and proofread it with the top AI models. It’s free to start. And if you want to go deeper on the data, the full ErrataBench results are open and interactive.
Quoting this post? All the data here is free to reuse with a link back.